SQL for Data Engineering
My full course to help you
build production data pipelines with SQL
All video lessons are free on YouTube
Supporter Access unlocks structure, guided practice, and community
Unlock Full Access


Pricing
FREE OPTION
Free
Features:
🎥 Full YouTube Course (14+ hours)
🧑💻 Two Complete Portfolio Projects
🔗 Links to Required Materials & Resources
📊 Real-World Dataset (2023 to mid-2025)
SUPPORTERS
$49
One-time payment — Supporter Access adds:
🧪 170+ Interview-Level SQL Problems
📺 Playlist-Style Lesson Videos
⏳ Progress Tracking
💬 Community Access
📝 Course Notes
📋 Cheat Sheets
🏆 Certificate of Completion
🎁 Full Real-World Dataset (2023–Present)
Course Outline
0️⃣ Course Intro
▾
Course Intro
▾
What is SQL
▾
Data & Pipeline Intro
▾
1️⃣ SQL Foundations
▾
SQL & Dataset Setup
▾
data_jobs database containing job posting facts and dimensions.data_jobs database with job postings, company, and skills tables for hands-on SQL practice.
Basic Keywords
▾
SELECT, FROM, WHERE, LIMIT, DISTINCT, and ORDER BY for querying data.SELECT * / FROMSELECT * to retrieve all columns and FROM to specify the table for querying job postings data.LIMITLIMIT to restrict the number of rows returned in query results for faster testing and data exploration.DISTINCTDISTINCT to remove duplicate values and return only unique rows from query results.WHEREWHERE clause to retrieve rows that meet specific conditions from the job postings table.IS NULL / IS NOT NULLIS NULL and IS NOT NULL operators to filter rows based on whether column values are missing or present.--) and multi-line (/* */) comments to document SQL queries for better code readability.ORDER BYORDER BY using ASC (ascending) or DESC (descending) to organize data by one or more columns.FROM, WHERE, SELECT, to ORDER BY and LIMIT for proper query construction.GROUP BY ALL and simplified column references for cleaner queries.
Comparison & Logical Operators
▾
=, !=, <, >, BETWEEN, IN) and logical operators (AND, OR, NOT) for filtering data.=, !=, <, >)=, !=, <, and > to filter job postings by salary, location, and other numeric or text values.AND, OR, NOT)AND, OR, and NOT logical operators to create precise data filters.BETWEEN, IN)BETWEEN for range filtering and IN to match values against a list of options in WHERE clauses.
Wildcards & Aliases
▾
%, _) with LIKE operator and AS keyword for creating column aliases in SQL queries.LIKELIKE operator using % (multiple characters) and _ (single character) wildcards to filter text data.ASAS keyword to alias columns and tables for clearer query results.LIKE, wildcards, and AS aliases to filter and display job postings with custom column names.
Arithmetic Operators
▾
* and / operators to multiply and divide numeric values for salary conversions and rate calculations.% to find remainders and identify even/odd numbers or distribute data into buckets.
Aggregate Functions
▾
COUNT, SUM, AVG, MIN, MAX, MEDIAN with GROUP BY and HAVING for data analysis.COUNT()COUNT() to count total rows or non-null values in a column for data analysis.COUNT(DISTINCT)COUNT(DISTINCT) to count unique values in a column, removing duplicates from the count.SUM()SUM() to add up numeric values like total salaries across job postings.AVG()AVG() to find mean values such as average salary for job roles.GROUP BYGROUP BY to organize rows into categories for aggregate calculations by job title or location.MIN() / MAX()MIN() and MAX() to identify lowest and highest salaries in datasets.MEDIAN()MEDIAN() to find the median salary, which is less affected by outliers than averages.HAVINGHAVING clause to apply conditions on aggregate functions like COUNT() or AVG().
Terminal Intro
▾
pwd, ls, cd)pwd (print working directory), ls (list files), and cd (change directory) to navigate file systems.mkdir, touch, rm)mkdir (make directory), touch (create file), and rm (remove files/folders) commands.
Local DuckDB Intro
▾
winget package manager for quick and easy setup via command line.brew install duckdb for streamlined setup.duckdb command to run SQL queries in an interactive local environment.motherduck_token environment variable and md: connection string prefix.
VS Code Intro
▾
Shift+Enter) to execute queries from editor to integrated terminal seamlessly.duckdb md: commands.
Data Modeling Pt.1
▾
ERD diagrams.ERD)information_schema)information_schema.schemata, information_schema.tables, and information_schema.columns to inspect database metadata and structure.
JOINs
▾
LEFT JOIN, RIGHT JOIN, INNER JOIN, and FULL OUTER JOIN for combining data from multiple related tables.foreign key relationships.LEFT JOINLEFT JOIN to return all rows from the left table and matching rows from the right table, with nulls for non-matches.RIGHT JOINRIGHT JOIN to return all rows from the right table and matching rows from the left table, with nulls for non-matches.INNER JOININNER JOIN to return only rows where matching values exist in both tables, excluding non-matches from results.FULL OUTER JOINFULL OUTER JOIN to return all rows from both tables, with nulls where matches don't exist on either side.
Order of Execution
▾
EXPLAIN and EXPLAIN ANALYZE for performance analysis.SELECT, FROM, JOIN, WHERE, GROUP BY, HAVING, ORDER BY, LIMIT.FROM, then WHERE, GROUP BY, HAVING, SELECT, ORDER BY, and finally LIMIT.EXPLAINEXPLAIN and EXPLAIN ANALYZE commands to visualize query execution plans and identify performance bottlenecks.
📊 SQL Exploratory Data Analysis — Project 1
▾
Project #1 Intro
▾
EDA #1 - In-Demand Skills
▾
COUNT, GROUP BY, JOIN, and ORDER BY on job postings data.
EDA #2 - Highest Paying Skills
▾
AVG, MEDIAN, GROUP BY, and ORDER BY with salary data.
EDA #3 - Most Optimal Skills
▾
LN, COUNT, AVG, and ranking calculations.
README.md Build
▾
README.md BuildREADME.md IntroREADME.md BuildREADME.md file with project description, setup instructions, and analysis results.
Git & GitHub Pt.1
▾
git config)git config command.git init, add, commit)git init, staging files with git add, and committing with git commit.git push, git pull)git push and git pull commands.
Share Project #1
▾
README.mdREADME.md and pushing project files with git push.
2️⃣ Production SQL
▾
Data Types
▾
CAST.INTEGER, VARCHAR, BOOLEAN, DATE, TIMESTAMP, and DOUBLE.DESCRIBE and querying information_schema.columns to check column data types.CAST OperatorCAST operator to change column types for calculations and comparisons.
DDL & DML Pt.1
▾
DDL & DML Pt.1DDL (Data Definition Language) and DML (Data Manipulation Language) commands.DDL vs. DML IntroDDL commands that modify structure and DML commands that modify data.CREATE / DROP DATABASECREATE DATABASE and DROP DATABASE commands.CREATE / DROP SCHEMACREATE SCHEMA and DROP SCHEMA commands.CREATE / DROP TABLECREATE TABLE and removing tables with DROP TABLE.INSERT INTOINSERT INTO with explicit values or from query results.ALTER TABLE - ADD / DROP COLUMNALTER TABLE ADD COLUMN and ALTER TABLE DROP COLUMN commands.UPDATEUPDATE with SET and WHERE clauses.ALTER TABLE - RENAME TABLE & RENAME/ALTER COLUMNALTER TABLE RENAME TO and ALTER TABLE RENAME COLUMN commands.
DDL & DML Pt.2
▾
DDL & DML Pt.2DDL and DML patterns including CTAS, views, and temp tables.DDL & DML - RefresherDDL and DML fundamentals before exploring advanced patterns.CTAS - CREATE TABLE AS SELECTCREATE TABLE AS SELECT (CTAS) pattern.CREATE VIEWCREATE VIEW to simplify complex queries.CREATE TEMP TABLECREATE TEMP TABLE for session-specific data processing.DELETEDELETE with WHERE clause filtering.TRUNCATETRUNCATE.
Subqueries and CTEs
▾
CTEsCTEs) for modular SQL.CTEs?CTEs for nested query logic.SELECT, FROM, and WHERE clauses to filter and transform data.CTEs - Common Table ExpressionsWITH (Common Table Expressions) for readable queries.EXISTSEXISTS and NOT EXISTS operators to filter based on subquery result existence.
DDL & DML Pt.3
▾
DDL & DML Pt.3CREATE TABLE and INSERT INTO.INSERT INTO with JOIN logic.UPDATE / INSERT / DELETE (Refresher)UPDATE, INSERT INTO, and DELETE commands before learning MERGE.MERGE INTOMERGE INTO using WHEN MATCHED, WHEN NOT MATCHED, and WHEN NOT MATCHED BY SOURCE clauses.CTAS vs. MERGECREATE TABLE AS SELECT for full rebuilds versus MERGE for incremental updates.
Data Modeling Pt.2
▾
OLTP vs OLAPOLTP databases (transactional) with OLAP databases (analytical) for different workloads.
CASE Expressions
▾
CASE ExpressionsCASE expressions.CASE ExpressionsCASE WHEN, THEN, ELSE, and END for data categorization.CASE: Engineering Use CasesCASE expressions to data engineering scenarios like salary standardization and bucketing.CASE expressions to standardize and categorize job salary data.
Date Functions
▾
EXTRACT, DATE_TRUNC, and time zones.EXTRACT()EXTRACT to get year, month, day, quarter from timestamps.DATE_TRUNC()DATE_TRUNC for month, quarter, year aggregations.AT TIME ZONEAT TIME ZONE for global data analysis.
SET Operators
▾
SET OperatorsSET operators for combining and comparing query results.UNION / INTERSECT / EXCEPTUNION, finding common rows with INTERSECT, and differences with EXCEPT.INTERSECT and EXCEPT to identify stable job markets and detect data quality issues.
Text & NULL Functions
▾
REPLACE / CONCATLOWER, UPPER, TRIM, REPLACE, and CONCAT for data cleaning.LOWER, TRIM, and CASE expressions together.NULLIF / COALESCECOALESCE to provide defaults and NULLIF to convert values to NULL.COALESCE instead of nested CASE expressions.
Window Functions
▾
GROUP BY for adding calculations without collapsing rows.OVER, PARTITION BY, and ORDER BY clauses.PARTITION BYPARTITION BY clause in window functions to divide result sets into groups for separate calculationsORDER BYORDER BY within window functions to control row ordering for calculations like running totalsPARTITION & ORDER BYPARTITION BY and ORDER BY in window functions for grouped, ordered calculationsSUM(), AVG(), COUNT(), MIN(), and MAX() with OVER clauseROW_NUMBER(), RANK(), and DENSE_RANK() window functionsLAG(), LEAD(), FIRST_VALUE(), and LAST_VALUE() navigation functions
Nested Functions
▾
ARRAY_AGG(), ARRAY_LENGTH(), and UNNEST() to collect and expand multiple valuesSTRUCT_PACK() to group named fields of different typesARRAY_AGG() and STRUCT_PACK() to create arrays of structured records for one-to-many relationshipsMAP() function and accessing values using bracket notationJSON_EXTRACT() and converting to structured types for analysisARRAY_AGG() and flattening them with UNNEST() for analysisSTRUCT_PACK() and UNNEST() to model complex job-skill relationships
Git & GitHub Pt.2
▾
git branch, git switch)git branch, git switch, and git checkout commandsgit add and git commit workflowgit merge when both branches have new commits
🏗️ End-to-End Data Pipeline — Project 2
▾
Project #2 Intro
▾
Build Data Warehouse
▾
git switch -c for isolated warehouse development workCREATE TABLE, primary keys, and FOREIGN KEY constraintsINSERT INTO with read_csv() functiongit merge and cleaning up branches with git branch -d
Build Flat Table Mart
▾
CREATE TABLE AS SELECT using LEFT JOIN and ARRAY_AGG(STRUCT_PACK()) for skill aggregationgit commit and merging to development branch
Build Skills Mart
▾
CREATE TABLE, dimension tables, and fact table using DATE_TRUNC() and EXTRACT() for time aggregationCOUNT() queries and joining fact tables with dimensions for enriched sample datagit add and git commit
Build Priority Mart
▾
CREATE TABLE and INSERT INTOMERGE INTO using WHEN MATCHED, WHEN NOT MATCHED, and WHEN NOT MATCHED BY SOURCE clausesgit merge
README.md Build
▾
README.md BuildREADME.md documentation for Project #2 repository and main course repoREADME.mdREADME.md with markdown formatting to document warehouse architecture, marts, and usage instructionsREADME.mdREADME.md with project links and course overview documentationgit commit and git merge
Share Project #2
▾
Course Resources
💽 Course Dataset — SQL Environment
This is the primary dataset used throughout the entire course. It contains real-world data engineering & analytics job postings (2023 to mid-2025) and is hosted in MotherDuck for instant querying.
🔗 Step 1 — Sign in to MotherDuck
Create your free account 👉 https://lukeb.co/motherduck
💻 Step 2 — Attach Database
Run this SQL inside the MotherDuck editor:

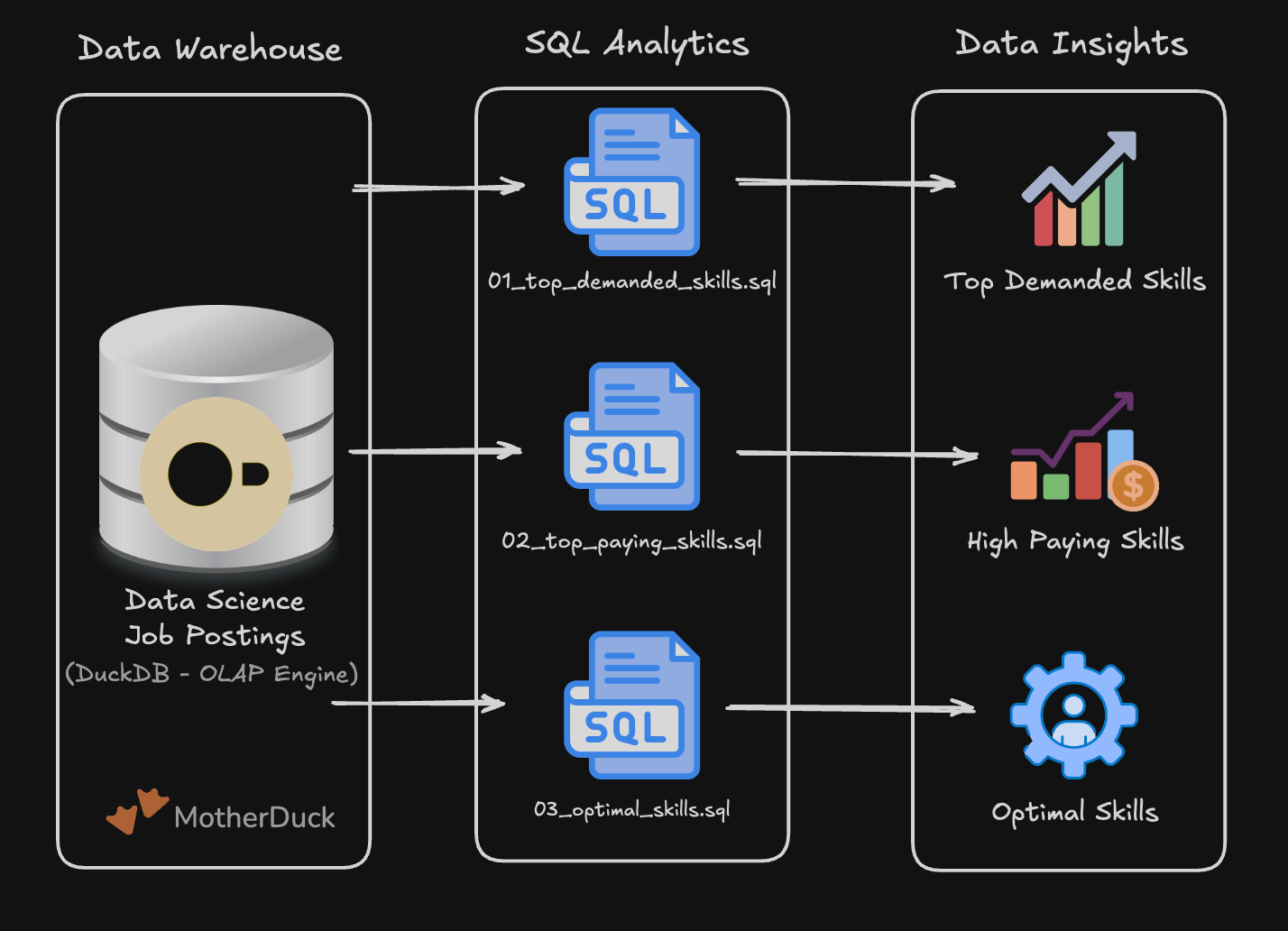
📊 Project 1 — SQL Exploratory Data Analysis
Explore real-world job data using SQL to uncover in-demand skills, salary trends, and hiring patterns. You’ll practice EDA techniques and build your first portfolio-ready project.
🔗 Project #1 Repo
👉 https://lukeb.co/sql-de-project1
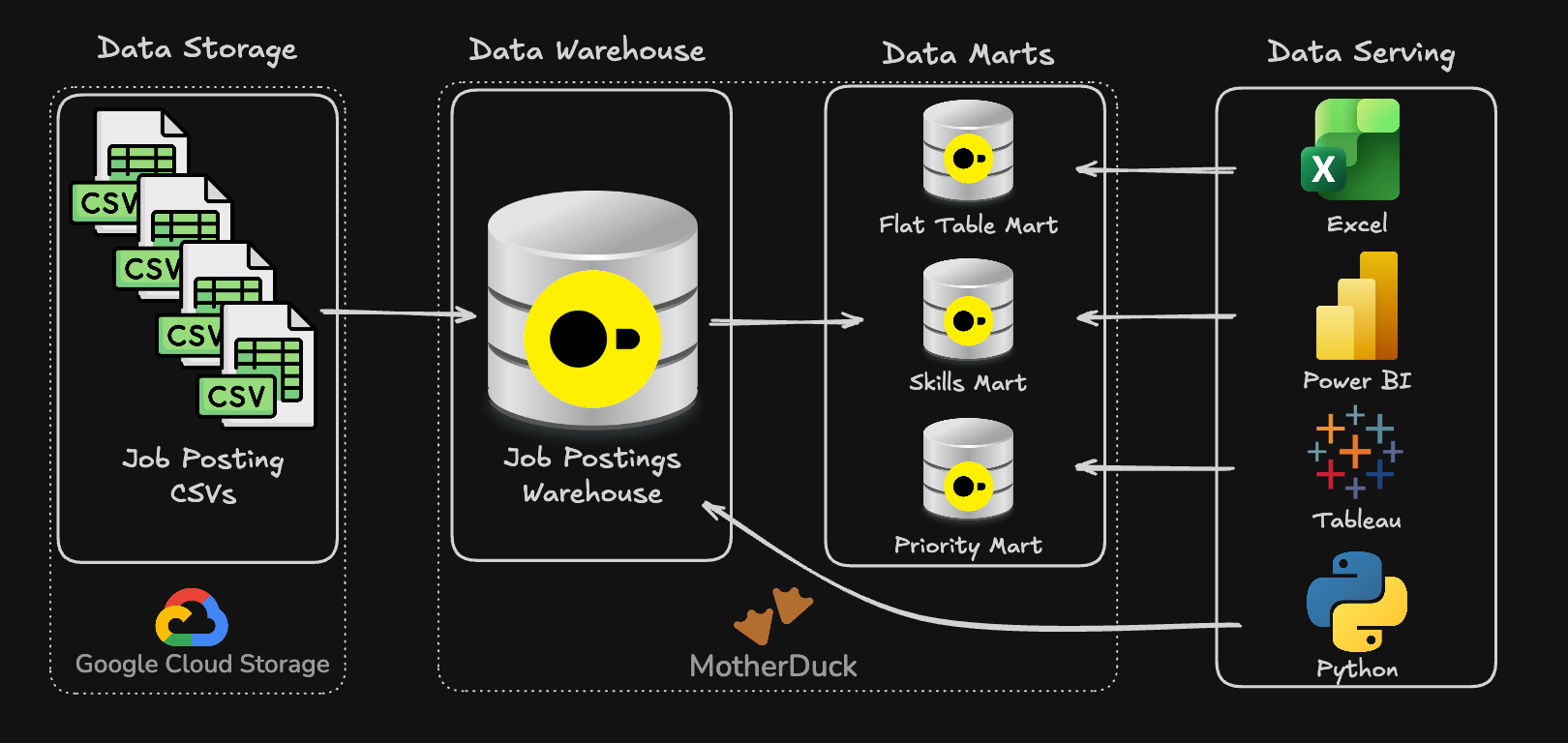
🏗️ Project 2 — Data Pipeline: Warehouse + Mart
Build a production-style SQL pipeline — modeling a data warehouse and creating analytical marts. You’ll apply data modeling, transformations, and best practices to deliver a second portfolio project.
🔗 Project #2 Repo
Supporter Resources
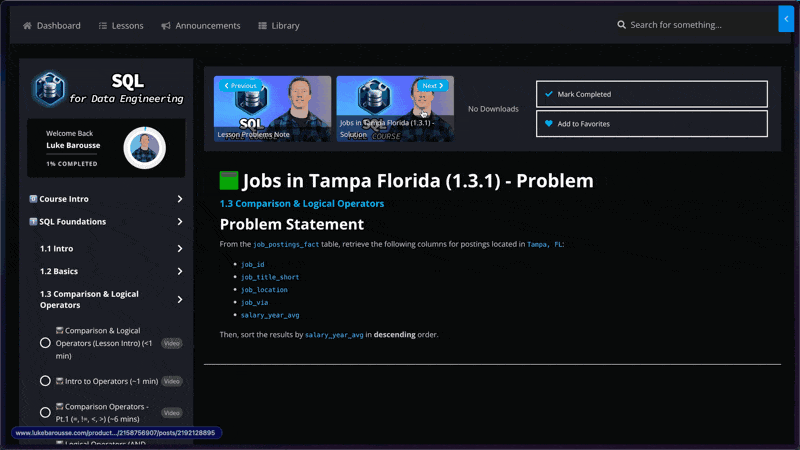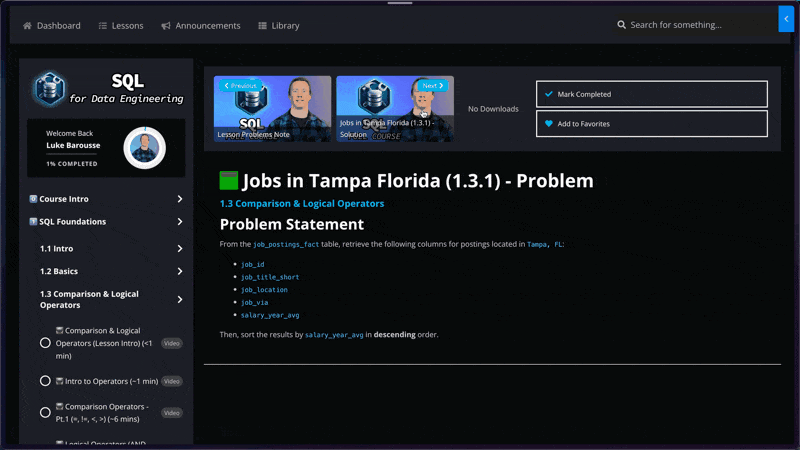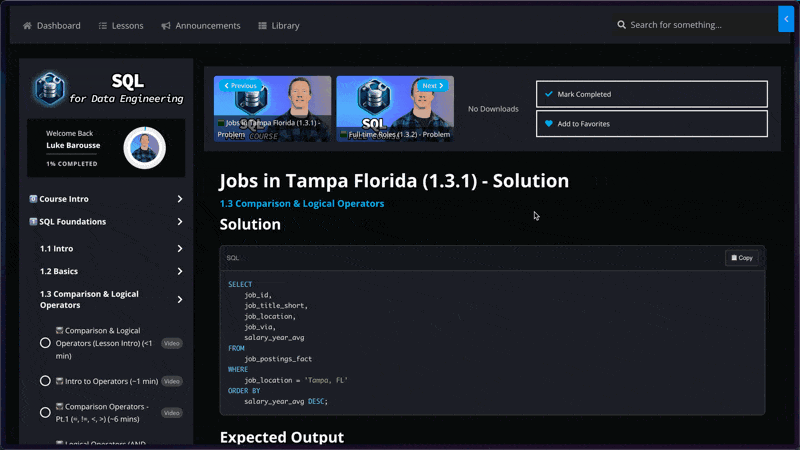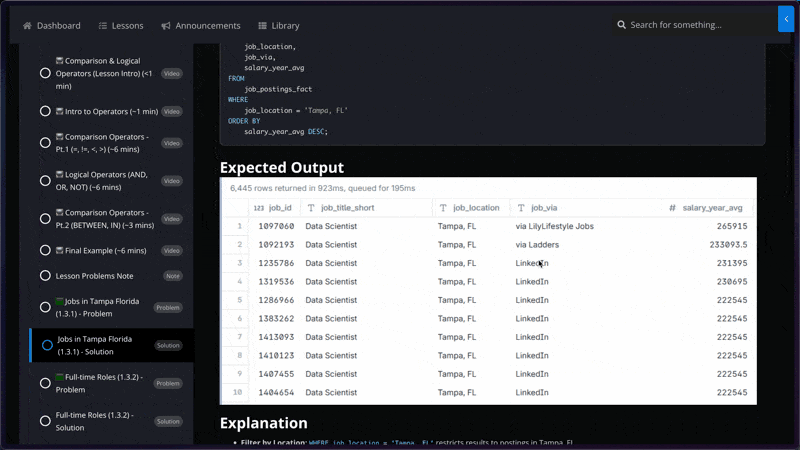
📝 Practice Problems
🧩 170+ Interview-Level Problems: Learn SQL faster with meticulously designed exercises spanning a range from easy to challenging
🔍 Detailed Solutions and Results: Every problem is accompanied by a comprehensive solution and your expected query results
📺 Structured Video Lessons
🚢 Navigate with Ease: Jump instantly to any lesson or specific topic within the course – no more wasting time scrubbing through hours of video to find what you need
🧠 Focused Learning: Master concepts more effectively with dedicated, bite-sized videos for each distinct lesson, allowing for better concentration and easier review


🗒️ Lesson Notes & Cheat Sheets
📖 Structured Lesson Notes: Step-by-step walkthroughs for every topic, helping you follow along with each lesson and understand why queries and pipelines are built the way they are
📋 Practical Cheat Sheets: Quick-reference guides for core SQL syntax, transformations, and data engineering concepts you’ll reuse across projects
✨ Certificate of Completion
🎖️ Certificate of Completion: Receive a certificate to validate your new skills and enhance your LinkedIn profile
🧑💻 Showcase Experience: Share how you used real-world data to help solve a problem for data professionals


About the Instructors
Luke Barousse - Course Instructor

🌎 Real-world Experience with SQL
Spearheaded innovative projects in collaboration with MrBeast's team, integrating popular tools like SQL & Python.
💡🤖 Sharing Knowledge about Data & AI
Guides a community of +600,000 data nerds in harnessing analytical tools to revolutionize their professional workflows.
🎓 Trusted Course Developer
Imparted wisdom to +30,000 learners on DataCamp in leveraging analytical tools to elevate their career efficiency.
Kelly Adams - Course Producer
🕹️ Hands on Experience with SQL
Driving strategic decisions within the social gaming industry at Golden Hearts Games, using popular tools like Google BigQuery (SQL), Dataform (dbt) and Looker.
📊 Analytics Engineering & Data Pipelines
Building scalable data pipelines that support product, finance, and growth teams with reliable, decision-ready metrics.
📹 Course Producer for Data Analytics Content
Educating an audience of +600,000 analysts about the latest data analytical tools to improve their professional skill sets.

Rikki Singh - Content Developer

🧑💻 Hands-on SQL & Analytics
Works across gaming, entertainment, and marketing—using Redshift and BigQuery to query and model data, and builds decision-ready dashboards in Looker and Tableau.
💼 Director-Level Operator
Leads analytics initiatives—bringing a “what matters to the business” lens to every lesson and project.
🎬 Course Producer for Data Analytics Content
Builds high-signal practice problems by benchmarking a wide range of learning platforms and question styles, then translating the best patterns into realistic, interview-ready exercises.
100% Satisfaction Guarantee or Your Money Back
⏱️ If you don’t feel the course problems and notes help you learn this tool as it has for countless others, I’ll refund your money!
📫 Email me within 30 days of purchasing the course on why you are unsatisfied, and I’ll return the full purchase price to you ASAP.
